
FTDI, large semiconductor manufacturer, recently released an update for its popular device drivers, that was bringing counterfeit chips into not usable state. However this made users uproar, because no end-user has an option to find out whether he obtains device with legal or counterfeit ICs. Luckily, FTDI has removed that update at the moment and there are ways to bring the devices back to life, but they still threat users with other options to annoy counterfeit users. The full story you can read, for example here: FTDI on counterfeit chip bricking: “Our intentions were honorable”
But let’s look closer at the chip, all the talks are about.
FT232RL is an extremely convenient chip. It serves as a bridge between USB virtual serial port on PC and UART on the device. Besides that it supports bit-bang mode, which makes it to support multiple protocols (e.g. SPI, I2C, etc.) in a software way. And as a bonus it has an internal circuitry to interface either 5V or 3V3 devices.
From a programming point of view, you have just to plug the device into the USB port and automatic driver installation will give you an access to the virtual serial port. Wanna bit-bang, then just download the library and API from the FTDI website and use it.
Ideal hardware for makers even at the listed prices.
But makers usually do it as a one device at a time connectivity. Other devices communication is commonly routed through the main gateway connected to the PC.
What happens if you are developer and need multiple devices connected at once?
Plug your devices into USB ports and Bang! Nothing is working.
You scratch your head and dive into Device Manager just to find out the following picture:
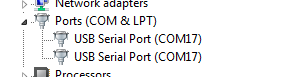
All the devices try to use the same virtual serial port number and as a result no devices can communicate at all.
Again after scratching your head you can find out, that you can change the port numbers in the properties.
But look at the specs. Port numbers are assigned in sequence. Really, FTDI?
Haven’t you enough time to fix that bug, since first FT232R release?
Is fighting for copyright is more important than your reputation, FTDI?


