
FTDI, крупный производитель полупроводников, недавно выпустил обновление драйверов для популярных устройств, которые «отключают» устройства изготовленные с использованием поддельных микросхем. Это вызвало волну негодования среди пользователей, потому как они практически не имеют возможности установить, используются ли в купленных ими устройствах настоящие или поддельные микросхемы. К счастью, FTDI убрал это обновление на данный момент. Кроме того имеются способы восстановления работоспособности устройств с поддельными микросхемами. Тем не менее компания по прежнему не оставляет своих планов по написанию таких драйверов, которые бы мешали пользоваться поддельными микросхемами. По подробнее об этом можно почитать, например, здесь: FTDI наносит ответный удар
Но взглянем на микросхему, о которой речь.
FT232RL — чрезвычайно удобна. Она служит мостом между виртуальным последовательным портом на кампьютере и UART на устройстве. Помимо этого, она поддерживает режим bit-bang, который позволяет реализовать программную поддержку многих протоколов (например SPI, I2C, и т.д.). В довесок идёт внутренняя схема, которая позволяет подключаться как линиям данных как при напряжении 5В, так и при 3,3В.
С точки зрения программирования, необходимо лишь подключить устройство с FT232 к порту USB, установить драйвер и вот уже есть доступ к виртуальному последовательному порту. Нужен режим bit-bang? Тогда скачиваете библиотеку с описанием на сайте FTDI и пользуетесь.
Идеальная железка для любых проектов, не смотря на заявленые цены.
Но обычно, такие устройства подключают по одному. Другие устройства уже общаются с компьютером через основное.
Что же делать, если ты разработчик и нужно подсоединить несколько устройств одновременно?
Подключаем и Бам! Ничего не работает.
После некоторого времени проведённого в экспериментах и выдирании волос с головы, обнаруживаем в Диспетчере Устройств следующую картину:
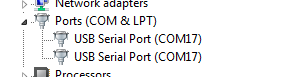
Все устройства пытаются занять один и тот же виртуальный порт и в результате ни одно из них не может общаться. Почесав затылок, можно обнаружить, что для каждого устройства, можно руками поменять номер порта в свойствах. Удобно ли? По моему абсолютно нет.
Но взглянем же в документацию. Она нам говорит, что номера портов назначаются последовательно. На самом деле, FTDI?
Эта ошибка присутствует ещё с самого первого релиза микросхемы.
Неужели не нашлось времени её починить? Неужели борьба за копирайт отнимает все ресурсы, и ведётся даже путём ухудшения репутации компании?


